The idea is to create a large neural network which itself generates other neural networks. The goal is to let the neural network find a way to just create new networks without any training needed.
I have two very different ideas on how to do this.
The first is not so practical to implement for any real world problems, but would be interesting to test on toy problems:
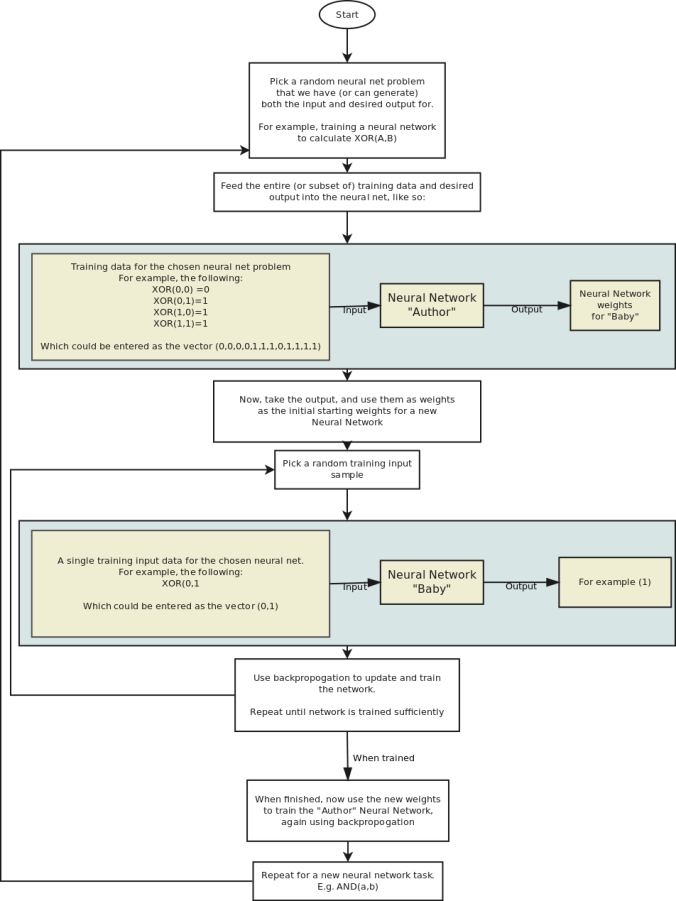
Now, this idea has many drawbacks. One problem is that when training the “Author” network in the first place, you typically have a fixed size input and so the training input will need to have a fixed size.
Since the input needs to be a fixed size, this means that you are limited to fixed size input and output for all the “Baby” Neural Networks that are generated, and that you must always have the same number of training samples.
Likewise, since the output is a fixed size, the weights has to be a fixed size, and so the number of layers, size of the layers, architecture, and so on has to be fixed for all possible Baby networks generated for a given Author.
