Heh, funny title.
I became interested in machine learning working for Nokia. I worked on Nokia’s Z Launcher application for Android. You can scribble a letter (or multiple), and it would recognize it and search for it. The app is available for download in the Play Store.

I worked on the Nokia Z Launcher’s handwriting recognition
Specifically I was tasked with optimizing the speed of the recognition. I don’t know if I can state any specifics on how the character recognition was done, but I will say that I managed to increase the speed of the recognition a hundred fold.
But this recognition was actually a relatively simple task, compared to modern day deep neural networks, but it really whet my appetite to understand more.
When Alpha Go beat Lee Sedol, I knew that I simply must understand Deep Neural Networks.
Below is my journey in understanding, along with my reflective thoughts:
- I started off naively implementing an LSTM neural network without any training.
I wanted to have a crude appreciation of the problems before I read about the solutions. My results are documented in my previous post here, but looking back it’s quite embarrassing to read. I don’t regret doing this at all however. - Next I did the Andrew Ng Coursera Machine Learning course.
This is an 11 week course in the fundamentals. I completed it along with all the coursework, but by the end I felt that my knowledge was about 20 years out of date. It was really nice to get the fundamentals, but none of the modern discoveries were discussed at all. Nothing about LSTM, or Markov Chains, or dropouts, etc.
The exercises are also all done in Matlab/Octave, which has fallen out of favour and uses a lot of support code. I certainly didn’t feel comfortable in implementing a neural network system from scratch after watching the course.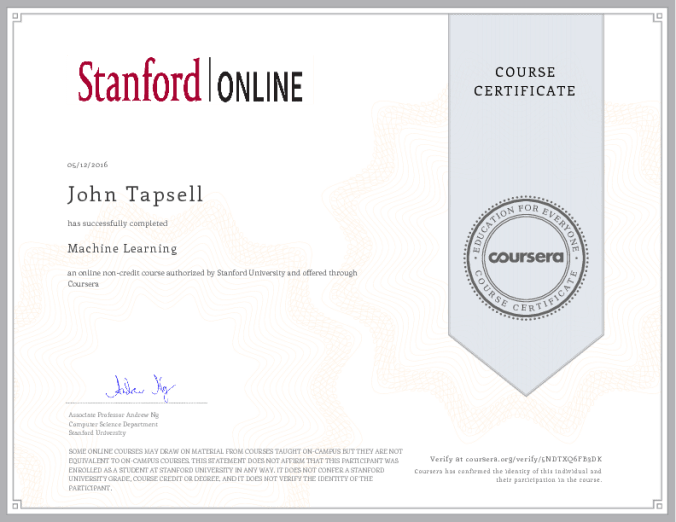
Passed the Coursera Machine learning course with 97.6% score.
The lecturer, Andrew Ng, was absolutely awesome. My complaints, really, boil down to that I wish the course was twice as long and that I could learn more from him! I now help out in a machine learning chat group and find that most of the questions that people ask about TensorFlow, Theano etc are actually basics that are answered very well by Andrew Ng’s course. I constantly direct people to the course.
- Next, Reinforcement Learning. I did a 4 week Udacity course UD820.
This was a done by a pair of teachers that are constantly joking with each other. I first I thought it would annoy me, but I actually really enjoyed the course – they work really well together. They are a lot more experienced and knowledgeable than they pretend to be. (They take it in turns to be ignorant, to play the role of a student). - I really wanted to learn about TensorFlow, so I did a 4 week Udacity Course UD730
Again I did all the coursework for it. I thought the course was pretty good, but it really annoyed me that each video was about 2 minutes long! Resulting in a 30 second pause every 2 minutes while it loaded up the next video. Most frustrating. - At this point, I started reading papers and joined up for the Visual Doom AI competition.
I have come quite far in my own Visual Doom AI implementation, but the vast majority of the work is the ‘setup’ required. For example, I had to fix bugs in their doom engine port to get the built-in AI to work. And it was a fair amount of work to get the game to run nicely with TensorFlow, with mini-batch training, testing and verification stages.
I believe I understand how to properly implement a good AI for this, with the key coming from guided policy search, in a method similar to that pioneered by google for robotic control. (Link is to a keynote at the International Conference on Learning Representations 2016). The idea is to hack the engine to give me accurate internal data of the positions of enemies, walls, health, etc that I can use to train a very simple ‘teacher’. Then use that teacher to supervise a neural network that has only visual information, thus allowing us to train a deep neural network with back-propagation. By alternating between teacher and student, we can converge upon perfect solutions. I hope to write more about this in a proper blog post. - The International Conference on Learning Representations (ICLR) 2016
Videos were absolutely fascinating, and were surprisingly easy to follow with the above preparation. - I listened to the entire past two years of the The Talking Machines podcast. It highlighted many areas that I was completely unfamiliar with, and highlighted many things that I knew about but just didn’t realise were important.
- I did the Hinton Coursera course on Neural Networks for Machine Learning, which perfectly complemented the Andrew Ng Coursera Course. I recommend these two courses the most, for the foundations. It is about 5 years out of date, but is all about the fundamentals.

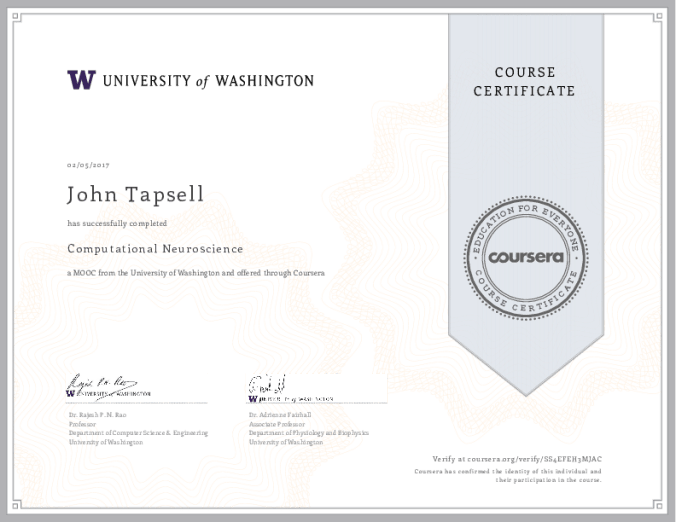
- I did the Computational Neuroscience course. The first half was interesting and was about, well, neuroscience. But the math lectures were in a slow monotonic tone that really put me straight to sleep. The second half of the course was just a copy of the Andrew Ng course (they even said so), so I just skipped all the lectures and did the exams with no problems. I really liked that they let you do the homework in python. It is easier in matlab, but I really wanted to improve my python datascience skills. The exams took way way longer than their predicted times. They would have 20 questions, requiring you to download, run and modify 4 programs, and say that you should be able to do it in an hour!
- I completed the IBM Artificial Intelligence class. This is the second most expensive AI class that I’ve done, at $1600 plus $50 for the book. I was really not at all impressed by it. Most of the videos are 1 minute long, or less, each. Which means that I’m spending half the time waiting for the next video to load up. The main lecturer gets on my own nerves – he wears a brightly colored Google Glass for no apparent reason other than to show it off, and speaks in the most patronizing way. You get praised continually for signing up to the course at the start. It’s overly specialized. You use their specific libraries which aren’t at all production ready, and you use toy data with a tiny number of training examples. (e.g. trying to train for the gesture ‘toy’ with a single training example!). Contrast this against the Google Self Driving course:
- The Google Self Driving course, which is $2400. This is much better than the IBM course. The main difference is that they’ve made the theme self driving cars, but you do it all in TensorFlow and you learn generic techniques that could be applied to any machine learning field. You quickly produce code that could be easily made production ready. You work with large realistic data, with large realistic neural networks, and they teach you use the Amazon AWS servers to train the data with. The result is code that can be (and literally is!) deployed to a real car.

