I implemented two medium-sized projects, one in Unreal Engine 4 and one in Unity 5.
Unfortunately these were both for clients, so I can’t talk about any specifics. I do, however, want to give some general thoughts on the comparison between them.
Pros and Cons:
- Unreal Engine 4 seems to have a lot more advanced features. But I didn’t personally use any of these advanced features. They didn’t seem easy to use.
- Unity 5 was much more intuitive for me to use.
- The Unity 5 asset store was so much nicer to use. I could buy an asset and import it into my game with a couple of clicks. With UE4 it seemed so much more difficult.
- UE4’s VR support simply didn’t work on a Mac. This sucked because my artists all use Macs. More annoyingly, it didn’t say why it didn’t work, it just simply disabled the Preview In VR button, giving no reason. And the reasons were written up in an Internal bug report (UE-11247 apparently) that the UE4 developers constantly refer to, but users aren’t actually allowed to view or see the status of!
- I much preferred having a managed language (C# or javascript) in Unity than the C++ support in UE4. Mistakes in C++ code meant crashing the whole app. It also led to long compile times. But a mistake in C# meant just having an exception and the app being able to easily recover from it.
- I tried really hard to get on with UE4’s Blueprint, which is basically a visual “programming” language. But implementing in a fairly simply mathematical formula would result in 20+ nodes. Implementing a simple polynomial like $latex y = 3x^2 + 2x + 5 $ was incredibly painful in dragging out nodes for each operation.

Blueprint quickly becomes a mess. This is a random example from the web.
- UE4’s blueprints become particularly annoying when users are asking questions about them. They’ll paste a screenshot of their blueprint saying that they have a problem. Someone else then has to try to decipher what is going on from a screenshot, with really no easy way to reproduce. Users who want to copy a blueprint have to do so manually, node by node..
I would really love for UE4 to mix in a scripting language, like Javascript. - UE4 has lots of cool features, but they are really difficult to just use. For example, it has a lot of support for adding grass. You can just paint grass onto your terrain.. except that you can’t because you don’t have any actual grass assets by default.
The official UE4 tutorials say that to add grass, you should import the whole 6.4 GB Open World Demo Collection to your project!
But then, even that isn’t enough because it doesn’t have any actual grass materials! You have to then create your own grass material which is quite a long process. This was really typical of my experience with UE4. Why not just have a single ‘grass’ asset that could be instantly used, and then let the user tweak it in more complicated ways if they want to later on?
Compare this to Unity. You go to: click on the tree or grass that you want, and that’s it. You can then start painting with that tree or grass immediately. If you later want to make your own trees, it comes with a tree editor, built in! - Unity’s support for Android was much better than UE4’s.
- UE4 taxed my system a lot more than Unity. For my beefy desktop, that was no problem. But the artists had Mac laptops that really struggled.
- I really like Unity’s GameObject plus Component approach. Basically, you make a fairly generic GameObject that is in your scene, and then you attach multiple components to it. For example, if you want a button, your button GameObject would have a mesh, a material, a renderer (to draw the material on the mesh), a hit box (to know when the user presses it) and presumably some custom script component that runs when you hit it.
And because your custom scripts are written in C# or javascript, you get lovely automatically introspection on the class variables, and any variables are automatically added to the GUI!
Overall, I guess I’ve become a unity fanboy. Which is a shame, because I started with UE4 and I really wanted to like it. I have been with UE4 for 2 years, and was a paying sponsor for a year.
I feel that the trouble is their different audiences. UE4 is obviously targeted towards much larger studios, who want advanced features and don’t care about built in assets etc. Unity on the other hand is targeted towards Indie developers who want to make quick prototypes and cheap products easily.
This has resulted into a sort of stigma against Unity projects, because there is a glut of rubbish games produced by novices in Unity. Unity charges about $1,500 per developer to remove the start-up Unity splashscreen, resulting in most indie developers not paying that fee. Only the good games which sell well can afford to remove that splashscreen.
The result being that if you start up a random indie game on steam greenlight, for example, and see the Unity splashscreen, you know that the game is unlikely to be that good. Hence a stigma.
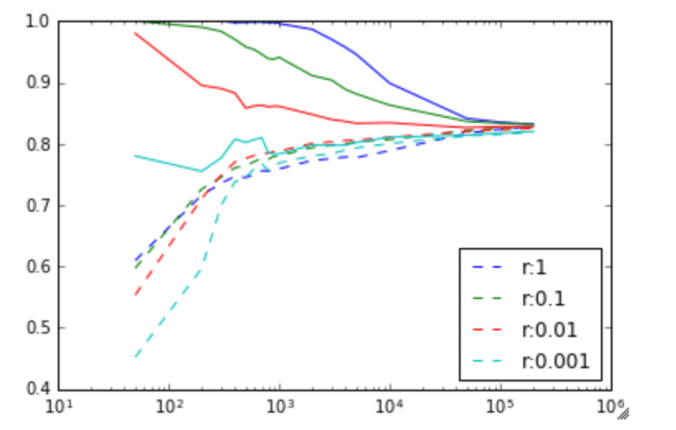
 ).
).
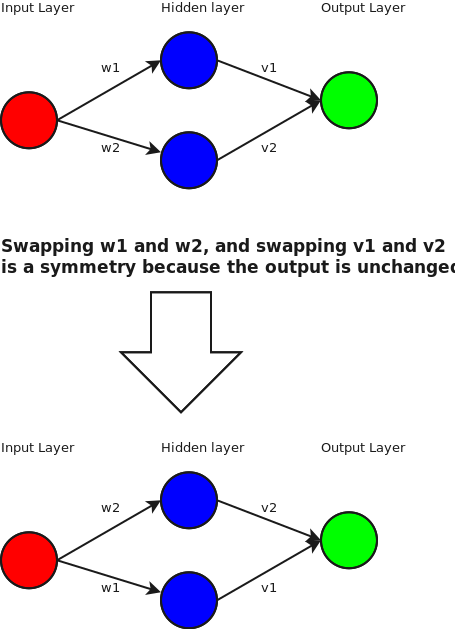
![[1,1]/\sqrt{2}](https://s0.wp.com/latex.php?latex=%5B1%2C1%5D%2F%5Csqrt%7B2%7D&bg=ffffff&fg=444444&s=0&c=20201002) and
and ![[1,-1]/\sqrt{2}](https://s0.wp.com/latex.php?latex=%5B1%2C-1%5D%2F%5Csqrt%7B2%7D&bg=ffffff&fg=444444&s=0&c=20201002) . Or in pictures:
. Or in pictures:
