Tons has been written about regularization, but I wanted to see it for myself to try to get an intuitive feel for it.
I loaded a dataset from google into python (a set of images of letters) and implemented a double for-loop to run a logistic regression with different test data sizes, and different regularization parameters. (The value shown in the graph is actually 
def doLogisticRegression(trainsize, regularizer):
fitmodel = linear_model.LogisticRegression(C=regularizer)
train_datasubset = train_dataset[0:trainsize,:,:].reshape(trainsize, -1)
x = fitmodel.fit(train_dataset[0:trainsize,:,:].reshape(trainsize, -1),
train_labels[0:trainsize])
return [fitmodel.score(train_datasubset, train_labels[0:trainsize]),
fitmodel.score(valid_dataset.reshape(valid_dataset.shape[0], -1), valid_labels)
]
print(train_dataset.shape[0])
trainsizes = [50,200,300,400,500,600,700,800,900,1000,2000,3000,4000,5000, 10000, 50000, 100000, 200000];
plt.xscale('log')
color = 0
plots = []
for regularizer in [1, 0.1, 0.01, 0.001]:
results = np.array([doLogisticRegression(x, regularizer) for x in trainsizes])
dashedplot = plt.plot(trainsizes, results[:,1], '--', label=("r:" + str(regularizer)))
plt.plot(trainsizes, results[:,0], c=dashedplot[0].get_color(), label=("r:" + str(regularizer)))
plots.append(dashedplot[0])
plt.legend(loc='best', handles=plots)
The result is very interesting. The solid line is the training set accuracy, and the dashed line is the validation set accuracy. The vertical axis is the accuracy rate (percentage of images recognized as the correct letter) and the horizontal axis is the number of training examples.
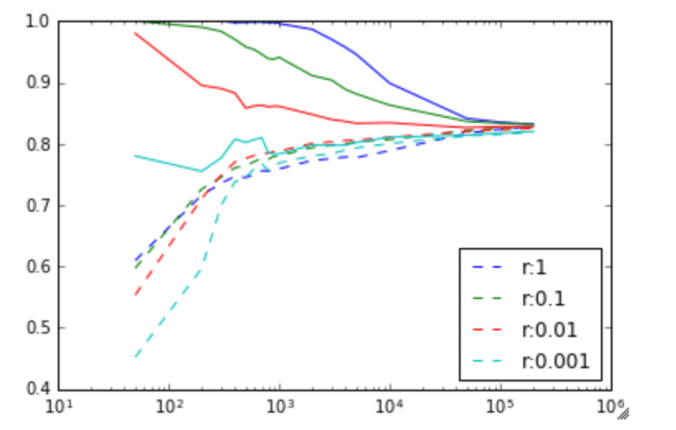
Image to letter recognition accuracy against training size, for various values of r = 1/regularization_factor. Solid line is training set accuracy, dotted line is validation set accuracy.
First, I find it fascinating that purely a logistic regression can produce an accuracy of recognizing letters at 82%. If you added in spell checking, and ran this over an image, you could probably get a pretty decent OCR system, from purely an logistical regression.
Second, it’s interesting to see the effect of the regularization term. At less than about 500 training examples, the regularization term only hurts the algorithm. (A value of 1 means no regularization). At about 500 training examples though, the strong regularization (really helps). As the number of training examples increases, regularization makes less and less of an impact, and everything converges at around 200,000 training samples.
It’s quite clear at this point, at 200,000 training samples, that we are unlikely to get more improvements with more training samples.
A good rule of thumb that I’ve read is that you need approximately 50 training samples per feature. Since we have 28×28 = 784 features, this would be at 40,000 training samples which is actually only a couple of percent from our peak performance at 200,000 training samples (which is 2000000/784=2551 training samples per feature).
At this point, we could state fairly confidently that we need to improve the model if we want to improve performance.
Stochastic Gradient Descent
I reran with the same data but with stochastic gradient descent (batch size 128) and no regularization. The accuracy (after 9000 runs) on the validation set was about the same as the best case with the logistic regression (81%), but took only a fraction of the time to run. It took just a few minutes to run, verses a few hours for the logistic regression.
Stochastic Gradient Descent with 1 hidden layer
I added a hidden layer (of size 1024) and reran. The accuracy was only marginally better (84%). Doubling the number of runs increased this accuracy to 86%.
