Neural networks have many internal symmetries. A symmetry is an operation that you can apply to the weights such that for all inputs the outputs are the same.
The trivial symmetry is the identity. If you multiply all the weights in a neural network by 1, then the output remains unchanged.
We can also move nodes around by swapping the weight in any hidden layer. For example:
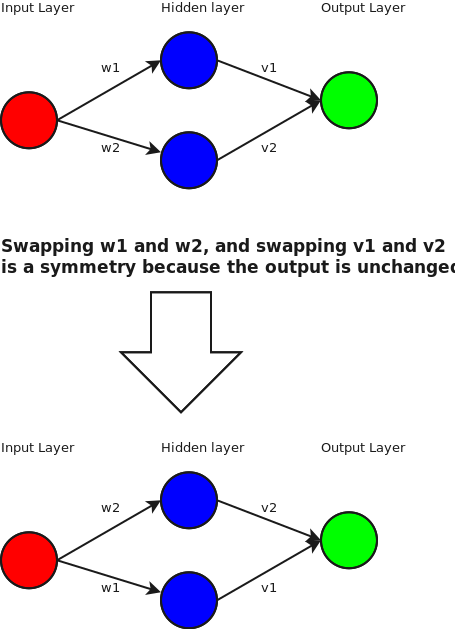
But what other symmetries are there? How is this useful?
Well, by itself, it’s not. But let’s get hand-wavy. Let’s say that we are using a ReLU activation function. What this means is that at our hidden node, if the final value is greater than 0, then the output at that node is the same value. if it’s negative, then the output is 0.
Let’s hand wave like crazy, and consider only the case where the node is activated (i.e the total value going into node is >=0). The output is equal to the input, and in this region it is linear.
So, ignoring the non-linear case, we can find an interesting symmetry. We can project to the basis ![[1,1]/\sqrt{2}](https://s0.wp.com/latex.php?latex=%5B1%2C1%5D%2F%5Csqrt%7B2%7D&bg=ffffff&fg=444444&s=0&c=20201002)
![[1,-1]/\sqrt{2}](https://s0.wp.com/latex.php?latex=%5B1%2C-1%5D%2F%5Csqrt%7B2%7D&bg=ffffff&fg=444444&s=0&c=20201002)

So, ignoring the non-linearity at the hidden layer, we find that we can actually weights in a more interesting fashion.
Now, what can we do with this?
Honestly, I’m not sure. One idea I had is if you’ve optimized a neural net and reached the peak that your training set can give you, you could apply this swap operation to random nodes and retrain and see if it helps. The effect is that you’re leaving the weights the same, but changing when the node activates. Hopefully I’ll have a better idea later.
