It is common to want to calibrate cameras for lens distortion.
First print out a standard chequerboard image, and take some photos of it from various angles. You can print out images, for example, here:
https://calib.io/pages/camera-calibration-pattern-generator
Here I assume these photos are in camera_cal/calibration*.jpg
Even if you ultimately want to calibrate the images from c++, python, javascript etc, the calibration itself can be done separately, in a more convenient language, producing a matrix that you can use pretty much anywhere. In my case, I calibrate in a jypter notebook, but use the matrix in c++.
%matplotlib inline
import numpy as np
import cv2
import glob
import matplotlib.pyplot as plt
#%matplotlib qt
# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((6*9,3), np.float32)
objp[:,:2] = np.mgrid[0:9,0:6].T.reshape(-1,2)
# Arrays to store object points and image points from all the images.
objpoints = [] # 3d points in real world space
imgpoints = [] # 2d points in image plane.
# Make a list of calibration images
images = glob.glob('camera_cal/calibration*.jpg')
# Step through the list and search for chessboard corners
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# Find the chessboard corners
ret, corners = cv2.findChessboardCorners(gray, (9,6),None)
# If found, add object points, image points
if ret == True:
objpoints.append(objp)
imgpoints.append(corners)
# Draw and display the corners
img = cv2.drawChessboardCorners(img, (9,6), corners, ret)
plt.imshow(img)
plt.show()
ret, camera_undistort_matrix, camera_undistort_dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
fname = images[8]
img = cv2.imread(fname)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, corners = cv2.findChessboardCorners(gray, (9,6),None)
print(ret)
img = cv2.drawChessboardCorners(img, (9,6), corners, ret)
dst = cv2.undistort(img, camera_undistort_matrix, camera_undistort_dist, None, camera_undistort_matrix)
img = np.concatenate((img, dst), axis=1)
plt.imshow(img)
cv2.imwrite("output_images/undistort_chessboard.png", img)
plt.show()

On the left is the original photo, and on the right is after applying the undistortion matrix warp.
import pickle
with open('camera_undistort_matrix.pkl', 'wb') as f:
pickle.dump((camera_undistort_matrix, camera_undistort_dist), f)
print(camera_undistort_matrix)
[[ 1.15777829e+03 0.00000000e+00 6.67113865e+02]
[ 0.00000000e+00 1.15282230e+03 3.86124659e+02]
[ 0.00000000e+00 0.00000000e+00 1.00000000e+00]]
img = cv2.imread("test_images/straight_lines1.jpg")
dst = cv2.undistort(img, camera_undistort_matrix, dist, None, camera_undistort_matrix)
img = np.concatenate((img,dst),axis=1)
img_rgb = cv2.cvtColor(np.asarray(img), cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
cv2.imwrite("output_images/undistort_straight_lines1.png", img)
plt.show()
In the top left is the original image, in the top right is the undistorted image. There is little difference to the eye, but the distortion lets us to now apply further distortions such as a perspective transform to provide an apparent “top-down view”.
It is also useful for applying other transforms key to stitching together images from multiple cameras.



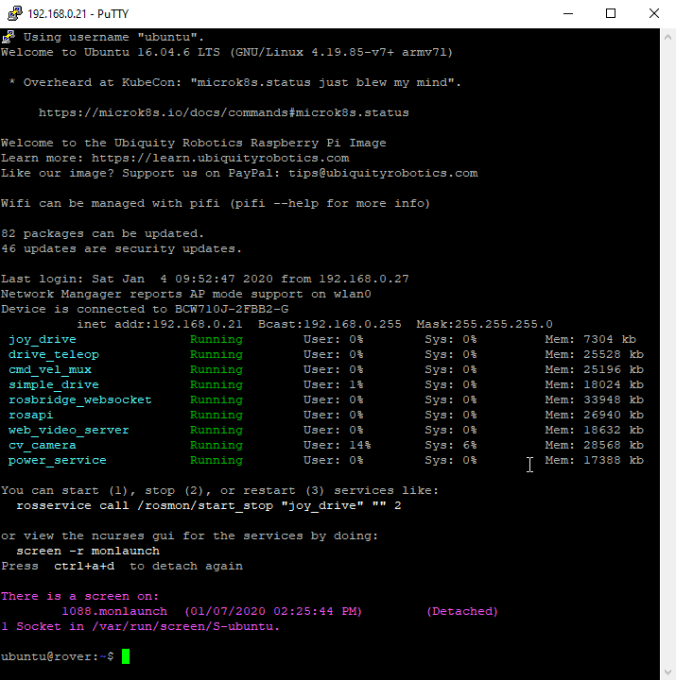

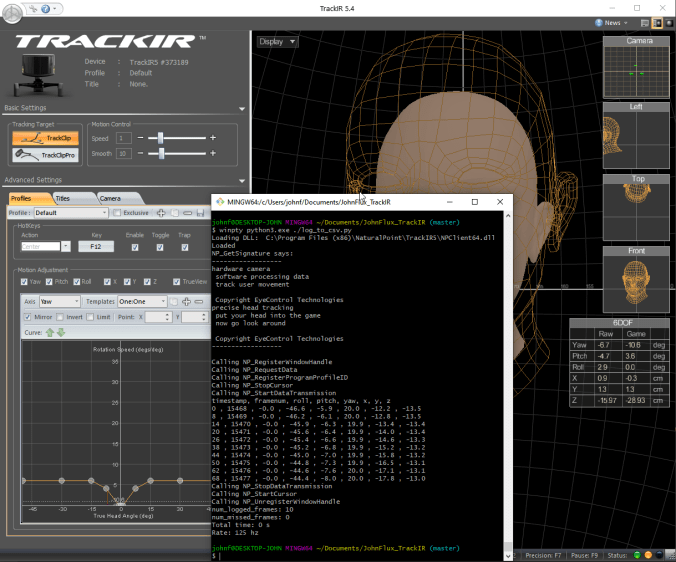



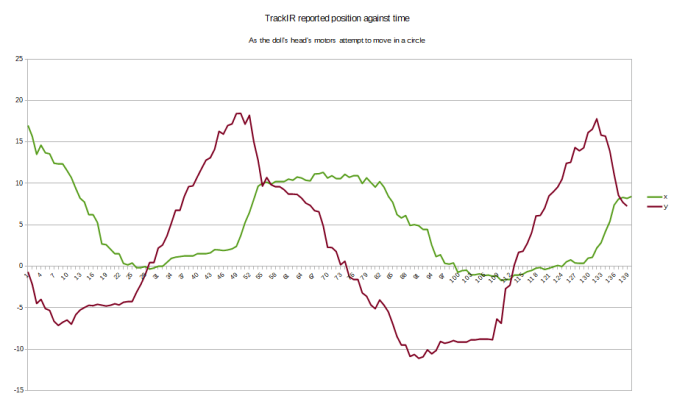





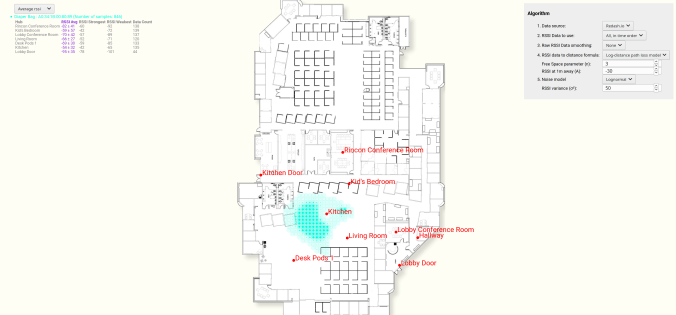

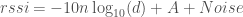

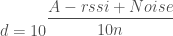


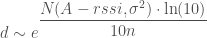
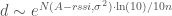
 is a
is a 


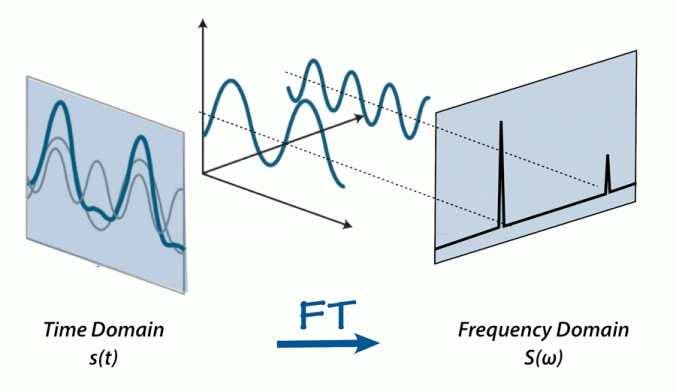



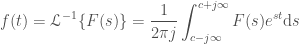

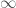 to
to  , and
, and 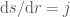 giving:
giving:
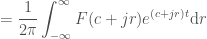

 “, but really it should be “Next two frequencies to add: … where
“, but really it should be “Next two frequencies to add: … where  ” since we are adding two frequencies at a time, in such a way that their imaginary parts cancel out, allowing us to keep everything real in the plots. I fixed this comment in the code, but didn’t want to rerender all the videos.
” since we are adding two frequencies at a time, in such a way that their imaginary parts cancel out, allowing us to keep everything real in the plots. I fixed this comment in the code, but didn’t want to rerender all the videos.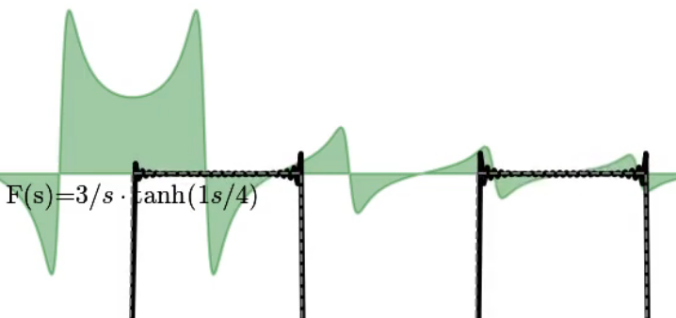
 . (A function that is 0 everywhere, except a sharp peak at exactly time = 0). In the S domain, this is a constant, meaning that we never converge. But visually it’s still cool.
. (A function that is 0 everywhere, except a sharp peak at exactly time = 0). In the S domain, this is a constant, meaning that we never converge. But visually it’s still cool.


























