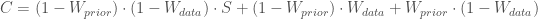The Laplace Transform is a particular tool that is used in mathematics, science, engineering and so on. There are many books, web pages, and so on about it.
My animations are now on Wikipedia: https://en.wikipedia.org/wiki/Laplace_transform
And yet I cannot find a single decent visualization of it! Not a single person that I can find appears to have tried to actually visualize what it is doing. There are plenty of animations for the Fourier Transform like:
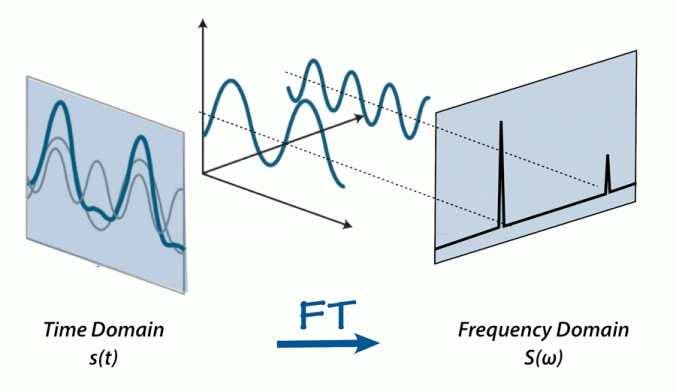
But nothing for Laplace Transform that I can find.
So, I will attempt to fill that gap.
What is the Laplace Transform?
It’s a way to represent a function that is 0 for time < 0 (typically) as a sum of many waves that look more like:

Graph of

Note that what I just said isn’t entirely true, because there’s an imaginary component here too, and we’re actually integrating. So take this as a crude idea just to get started, and let’s move onto the math to get a better idea:
Math
The goal of this is to visualize how the Laplace Transform works:

To do this, we need to look at the definition of the inverse Laplace Transform: (Using Mellin’s inverse formula: https://en.wikipedia.org/wiki/Inverse_Laplace_transform )
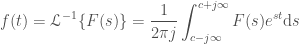
While pretty, it’s not so nice to work with, so let’s make the substitution:

so that our new limits are just 

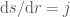

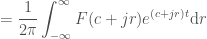
Which we will now approximate as:

Code
The code turned out to be a bit too large for a blog post, so I’ve put it here:
https://github.com/johnflux/laplace-transform-visualized/blob/master/Laplace%20Transform.ipynb
Results
Note: The graphs say “Next frequency to add: … where 

A cubic polynomial:
A cosine wave:
Now a square wave. This has infinities going to infinity, so it’s not technically possible to plot. But I tried anyway, and it seems to visually work:
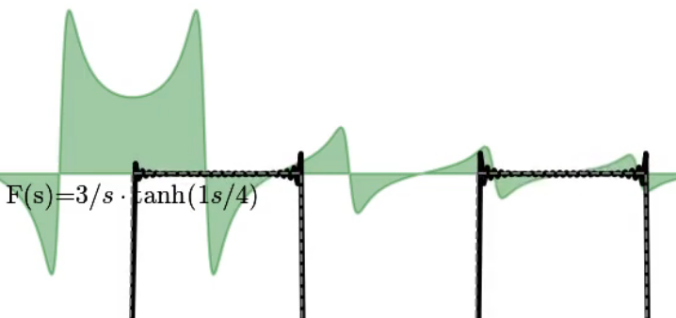
Note the overshoot ‘ringing’ at the corners in the square wave. This is the Gibbs phenomenon and occurs in Fourier Transforms as well. See that link for more information.
Now some that it absolutely can’t handle, like: 
Note that this never ‘settles down’ (converges) because the frequency is constantly increasing while the magnitude remains constant.
There is visual ‘aliasing’ (like how a wheel can appear to go backwards as its speed increases). This is not “real” – it is an artifact of trying to render high frequency waves. If we rendered (and played back) the video at a higher resolution, the effect would disappear.
At the very end, it appears as if the wave is just about to converge. This is not a coincidence and it isn’t real. It happens because the frequency of the waves becomes too high so that we just don’t see them, making the line appear to go smooth, when in reality the waves are just too close together to see.
The code is automatically calculating this point and setting our time step such that it only breaksdown at the very end of the video. If make the timestep smaller, this effect would disappear.
And a simple step function:
A sawtooth:






























 . i.e. treating the highly improbable as truth. Perhaps what Sherlock should have said is that it is far more likely that you were simply mistaken in elimination! i.e. your prior or data was wrong!
. i.e. treating the highly improbable as truth. Perhaps what Sherlock should have said is that it is far more likely that you were simply mistaken in elimination! i.e. your prior or data was wrong! plus a
plus a 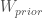 chance of ‘wtf’: aka:
chance of ‘wtf’: aka:
 plus a
plus a 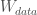 chance of ‘wtf’: aka:
chance of ‘wtf’: aka:
 (note that
(note that  is proportionate to a new Gaussian scaled by a factor
is proportionate to a new Gaussian scaled by a factor  )
)
 We know that the area must equal 1 for a PDF, so we can determine the scale factor C. See Appendix below for any technical details, including the formula for S and C.So we have a solution, but the solution is a gaussian mixture model – a sum of a gaussian for the combination, a gaussian for the prior, and a gaussian for the data. So let’s simply pick the one with the highest probability, and roll the other two into the WTF weight.
We know that the area must equal 1 for a PDF, so we can determine the scale factor C. See Appendix below for any technical details, including the formula for S and C.So we have a solution, but the solution is a gaussian mixture model – a sum of a gaussian for the combination, a gaussian for the prior, and a gaussian for the data. So let’s simply pick the one with the highest probability, and roll the other two into the WTF weight.

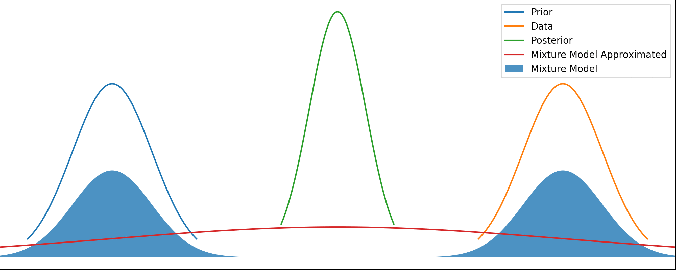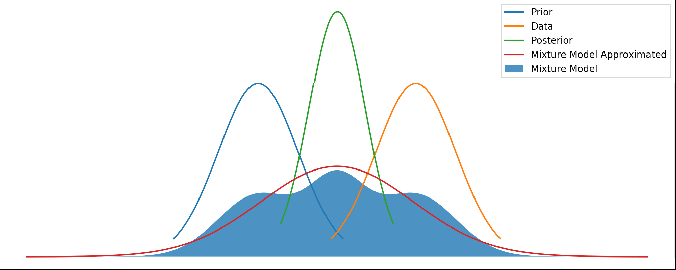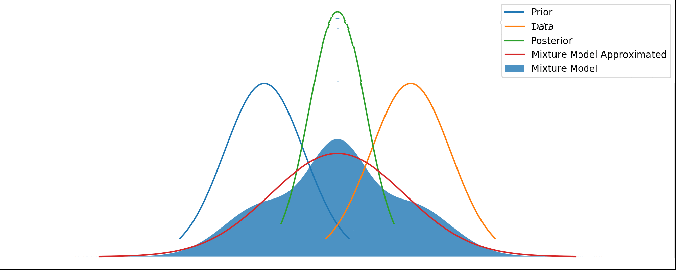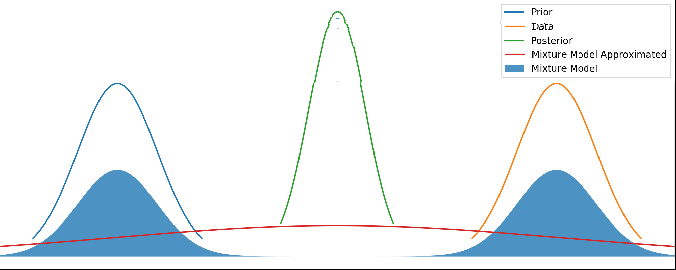

 where it can be anywhere between A and -A. We can take A to be large or even take the limit to infinity.
where it can be anywhere between A and -A. We can take A to be large or even take the limit to infinity.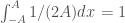 , and can set the
, and can set the  since:
since:  which tends to 0 as
which tends to 0 as  .
.